![[レポート] Deep dive into Amazon DynamoDB zero-ETL integrationsに参加しました #AWSreInvent #DAT348](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg?w=3840&fm=webp)
[レポート] Deep dive into Amazon DynamoDB zero-ETL integrationsに参加しました #AWSreInvent #DAT348
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
データ事業本部のkobayashiです。ラスベガスで開催されていたre:Invent2024に現地参加しました。
本記事は AWS re:Invent 2024 のセッション「DAT348 | Deep dive into Amazon DynamoDB zero-ETL integrations」のセッションレポートです。
このセッションでは、DynamoDBのZero-ETL統合についての説明であり、DynamoDBのZero-ETL統合を使うことでカスタムETLパイプラインの必要性を最小限に抑え、データ取り込みやレプリケーションなどの一般的なユースケースに対してマネージドなデータパイプラインをつかうメリットの解説がありました。また最近のリリースとして、DynamoDBからRedshiftへの統合とDynamoDBからSagemaker Lakehouseへの統合が紹介されました。
デモンストレーションでは、DynamoDBからLakehouseへのゼロETL統合のセットアップが実演され、その使いやすさと効率的なデータレプリケーションを解説されました。
セッションの概要
タイトル
DAT348 | Deep dive into Amazon DynamoDB zero-ETL integrations
概要
Amazon DynamoDB is a serverless, NoSQL, fully managed database with single-digit millisecond performance at any scale. DynamoDB lends itself to easy integration with several other AWS services. In this session, dive deep into zero-ETL integrations between Amazon DynamoDB and Amazon SageMaker Lakehouse, Amazon OpenSearch Service, and Amazon Redshift. Learn from AWS experts about how these integrations can reduce operational burden and cost, allowing you to focus on creating value from data instead of preparing data for analysis
- Level: 300
- Session Type: Breakout session
スピーカー
- David Gardner, Database Specialist Solution Architecture, AWS
- Sean Ma, Principal Product Manager, Amazon Web Services
内容
はじめにアジェンダです。
- Zero-ETLの概要とビジネスケース
- Zero-ETLの基本的な説明と、ビジネスにおけるその重要性や利点についての解説
- サービス概要
- DynamoDBとRedshiftの簡単な説明
- Zero-ETLのアーキテクチャと詳細レビュー
- DynamoDBのZero-ETL統合の説明
- デモ
- まとめ
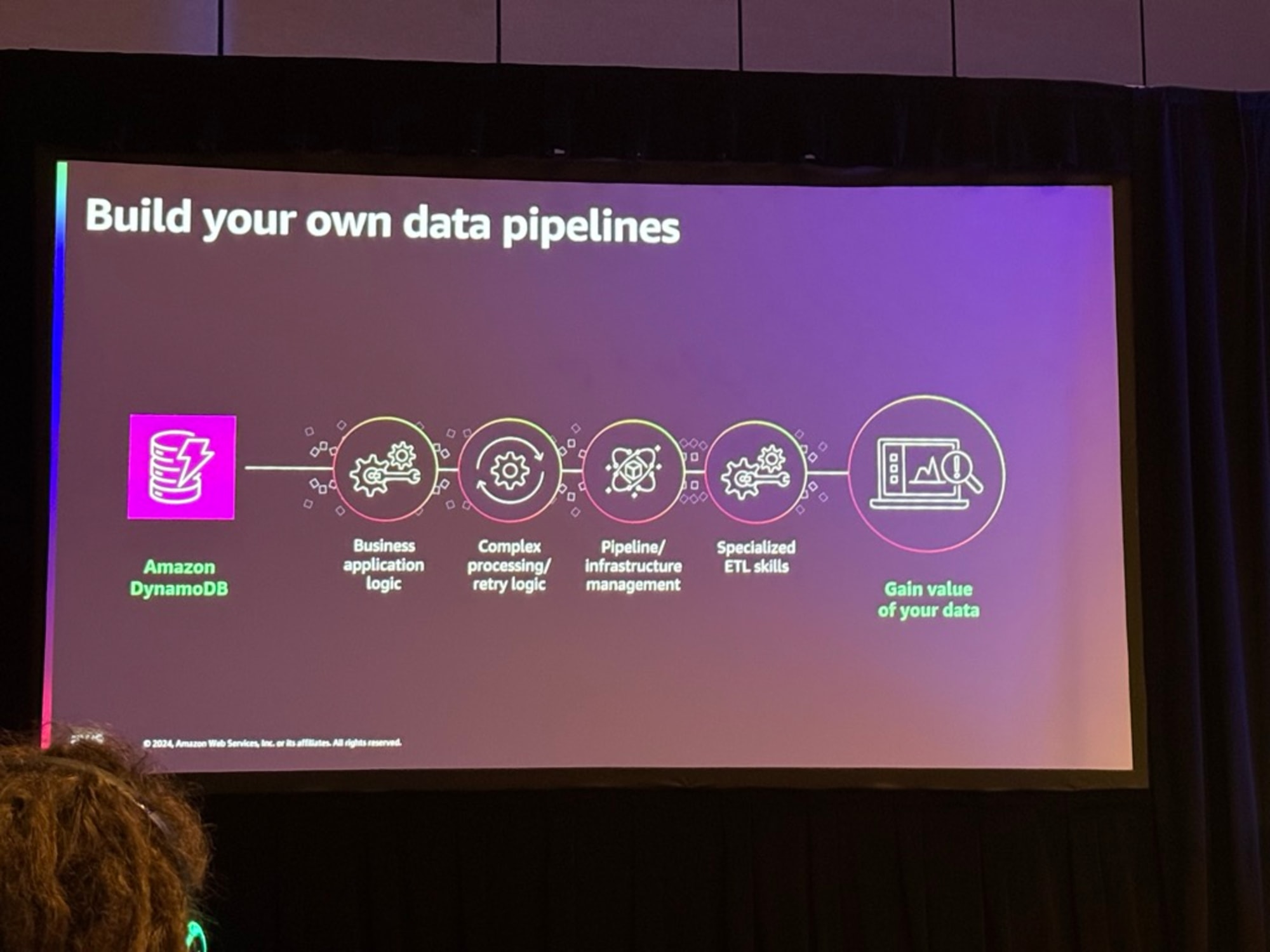
Zero-ETL統合のメリットの解説がありました。
従来のETLパイプラインの構築は特定のスキルセットと専門チームを必要とし運用と保守に多くの労力がかかることが課題だったが、Zero-ETLは、AWSが管理する完全に管理されたデータパイプラインのセットで、一般的なユースケースのためのETLパイプライン構築の必要性を最小限に抑え、最近ではDynamoDBからRedshiftへの統合や、DynamoDBからSageMaker Lakehouseへの統合など、新しい機能が追加されている。
ゼロETLの主な利点として以下の3点がある。
- 俊敏性の向上:AWSがETLパイプラインを構築・維持するため、チームはビジネス変換に集中できる。
- 効率性:クラウドベースで従量課金制のため、スケーリングの心配がない。
- 中央集権的なデータガバナンス:データが中央で管理され、安全に保たれ、他のAWSサービスとの統合が容易。
これによりデータエンジニアは複雑なETLプロセスの管理から解放され、より価値の高いタスクに集中できるようになる。また、組織全体でデータへのアクセスと活用が容易になり、ビジネスインサイトの獲得が加速されるとのことでした。

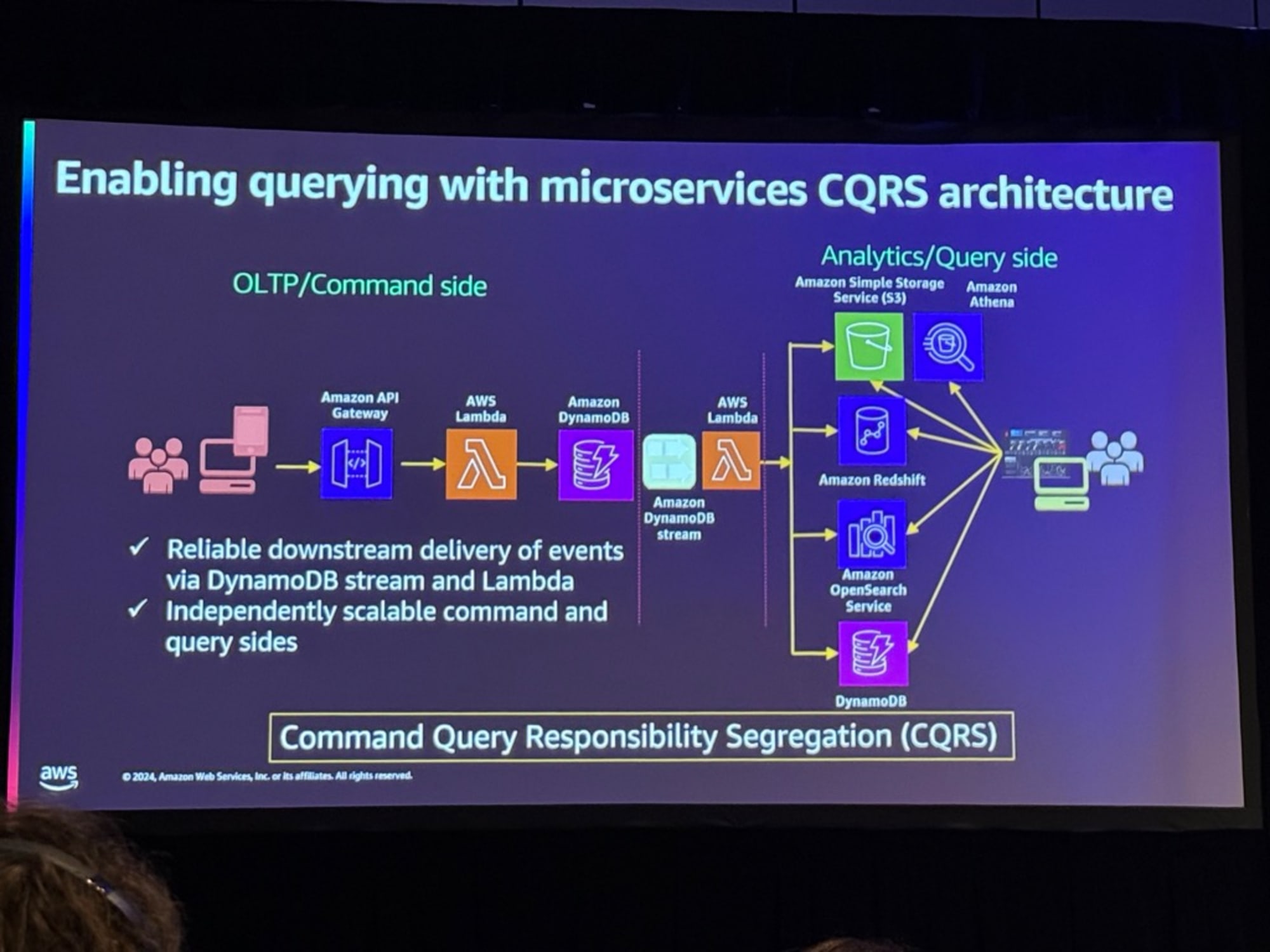
次にDynamnoDBとRedshiftの簡単な解説がありました。

コマンド・クエリ・レスポンス分離(CQRS)と呼ばれるアーキテクチャアプローチの解説がありました。
運用データベースを持っているが、その上でレポートや分析を行いたいという古典的な問題に対応したもので、このアーキテクチャは、これらを別々のストリームに分離するため、誰かが分析クエリを実行しても、運用データベースシステムに影響を与えないものであるとのことでした。
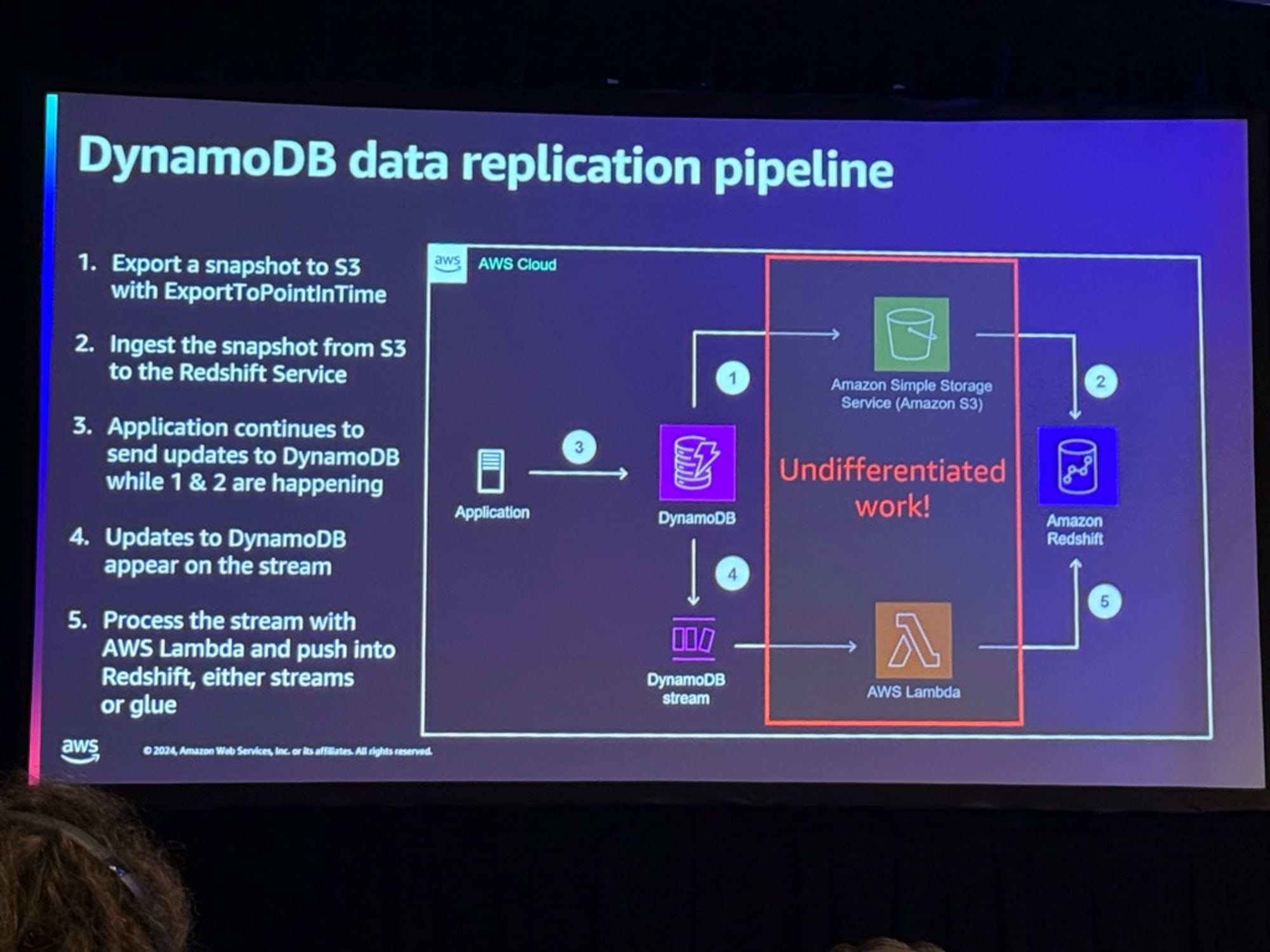
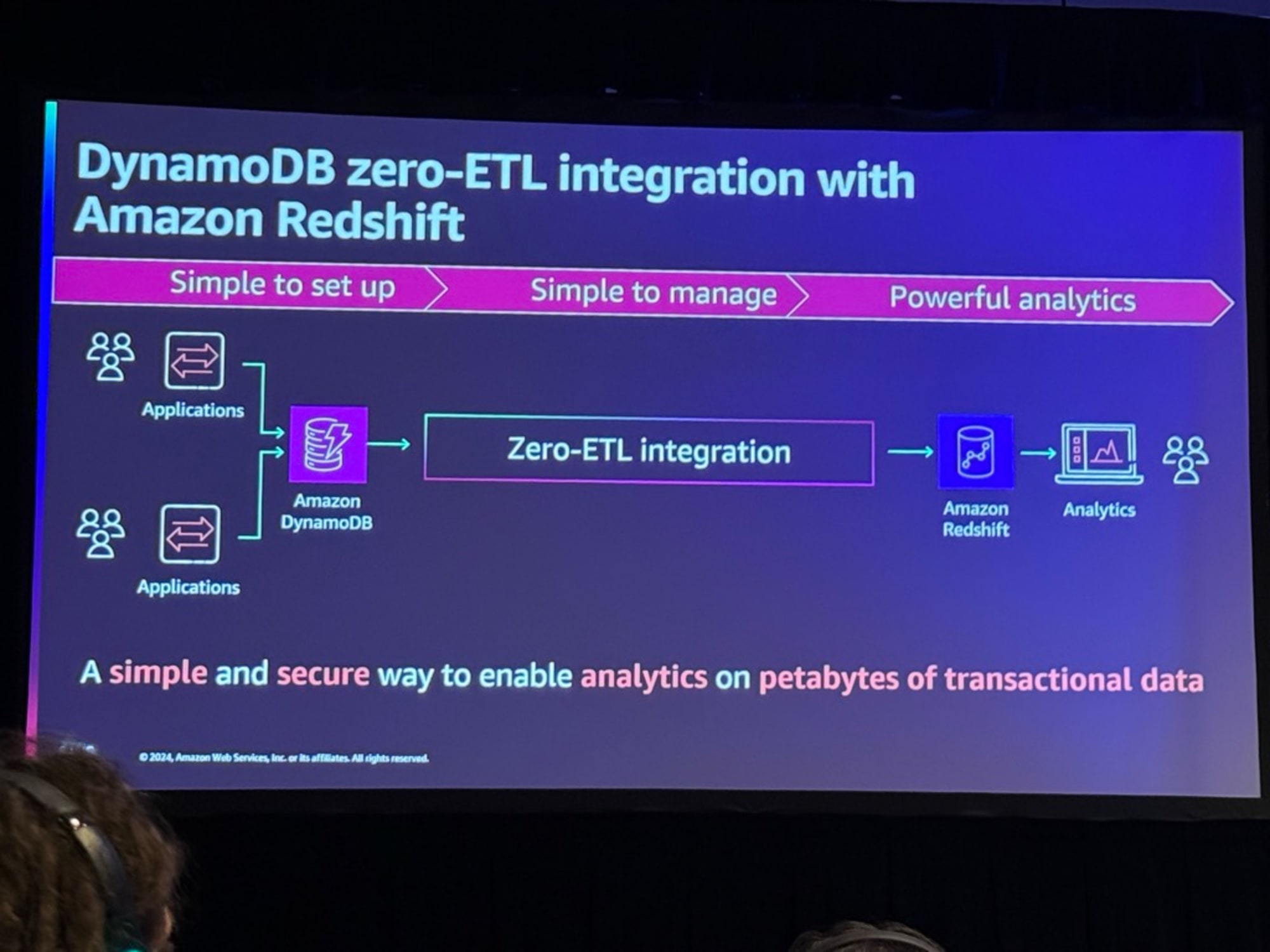
DynamoDBのデータリプリケーションパイプラインの解説がありました。
- 中央の大きな赤い部分が従来データエンジニアが担当してきた領域でバッチETLプロセス
- ここで何かがトラブルがあったり、誰かが新しい列を追加する変更作業が必要
- これをZero-ETLの機能として置換できる
次にZero-ETLの解説がありました。
- セットアップはマネージメントコンソールから簡単に行え管理も簡単である。
- ETLパイプラインをメンテする工数をより多くのビジネス価値を追加する機能に使える
- DynamoDBからRedshiftへのEnd-to-Endのレプリケーションが15-30分で完了する
- スケールに関してはサーバーレスで自動的にスケールアップする
- コーディングは一切必要ない
- 複数のDynamoDBテーブルを一つのRedshiftクラスターに統合でき、DynamoDBでは実現できなかったテーブル結合をRedshift上で行うことができる

次にデータレイアウトについて解説がありました。
- Zero-ETLプロセスの一部として、パーティションキーとソートキーをDynamoDBとRedshift間で引き継ぐ
- DynamoDBテーブルの他の属性は、Redshiftにスーパーデータ型として保存する
- クロスアカウントでも利用可能

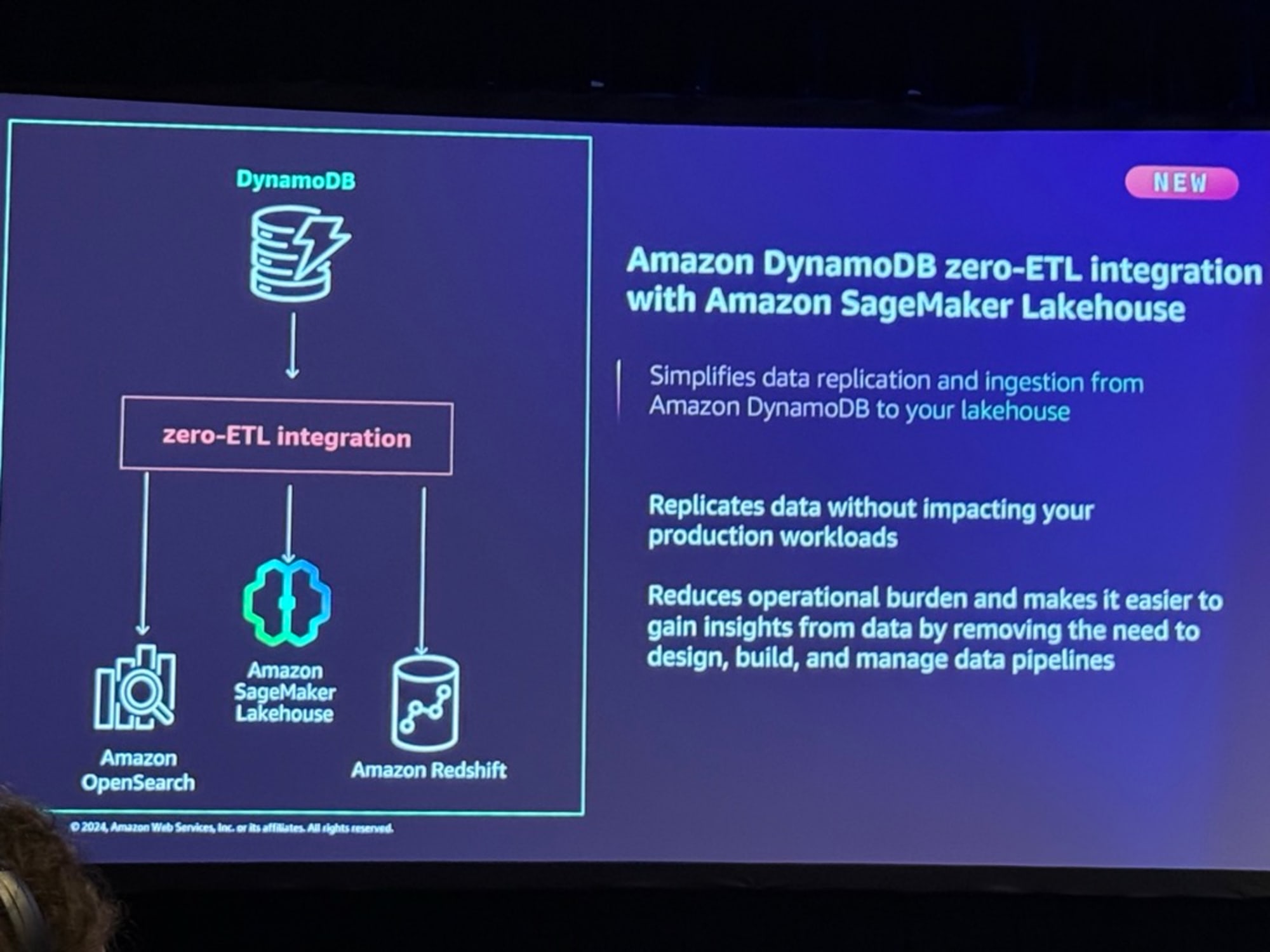
ここでNextGen SageMakerとZero-ETL統合の話になりました。
Zero-ETLとLakehouseの組み合わせにより、データウェアハウス、データレイク、DynamoDBのような運用データベース、そしてアプリケーションのデータを1つの場所に統合できるようになったとのことです。

また、
- Lakehouseはオープンで相互運用可能な安全なデータ基盤を提供し、RedshiftとS3の利点を組み合わせた単一のデータストレージを実現し、Lake FormationとGlue Data Catalogによる統合的なメタデータ管理を可能にする。
- SageMaker LakehouseへのDynamoDBからのゼロETLを追加する新機能も発表され、データレプリケーションと取り込みのニーズを簡素化し、本番ワークロードに影響を与えずにデータを利用可能にすることができるようになった
とのことでした。

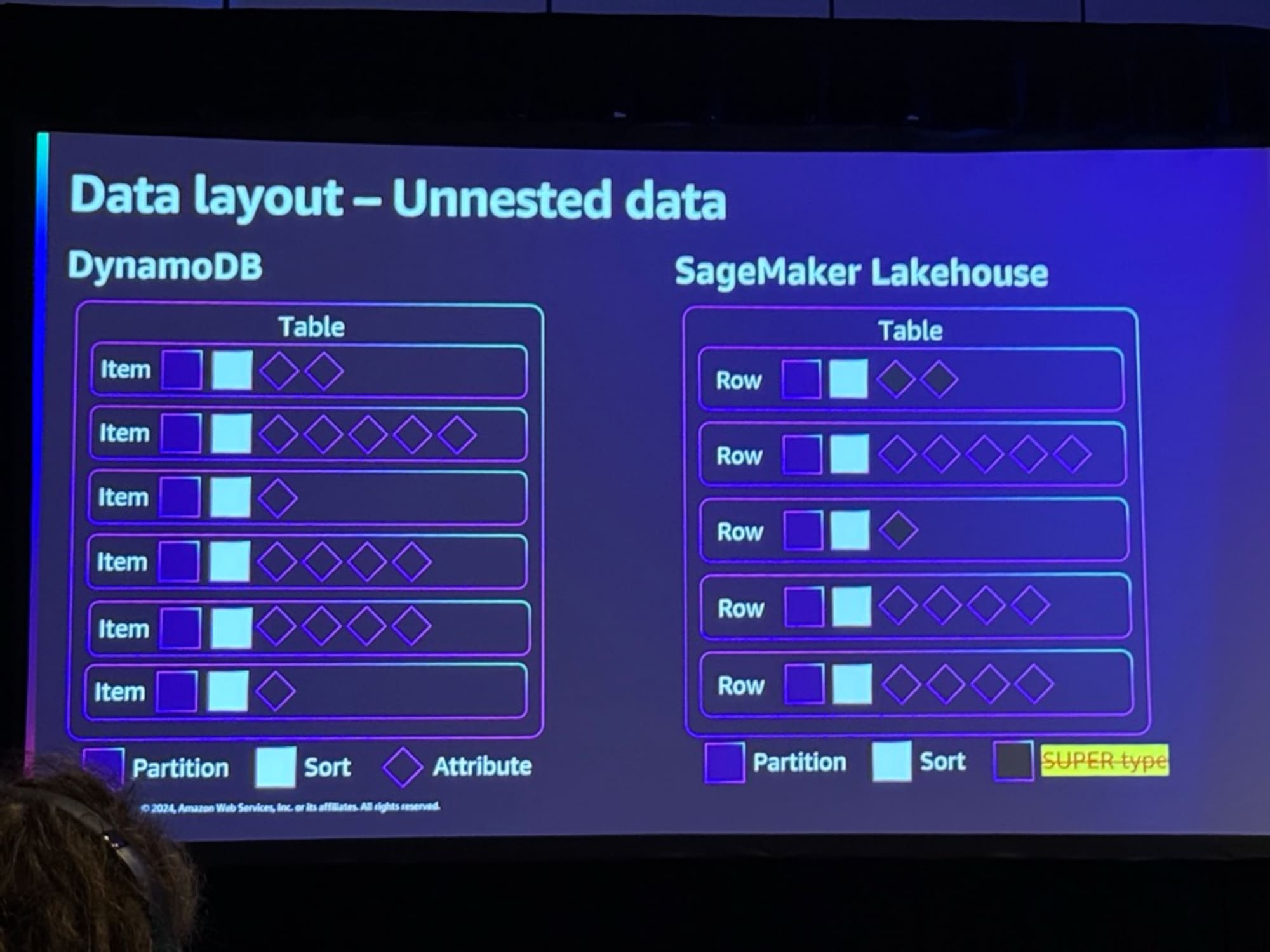
上記の統合により先に解説したデータレイアウトも大きく変わったそうです。
- Lakehouseはデータレイクなので、スーパータイプの機能がない
- そのためデータをアンネスト(入れ子構造を解除)して、より定義された形式にする必要がより一般的になる
- これにより、他のシステム(特にSparkエンジンやAthenaなど)からデータを読み取る際に簡単にアクセスできるようになる
- 他のシステムもデータを活用したい場合、アンネストされた形式でLakehouseに保存されているため簡単にデータを扱える
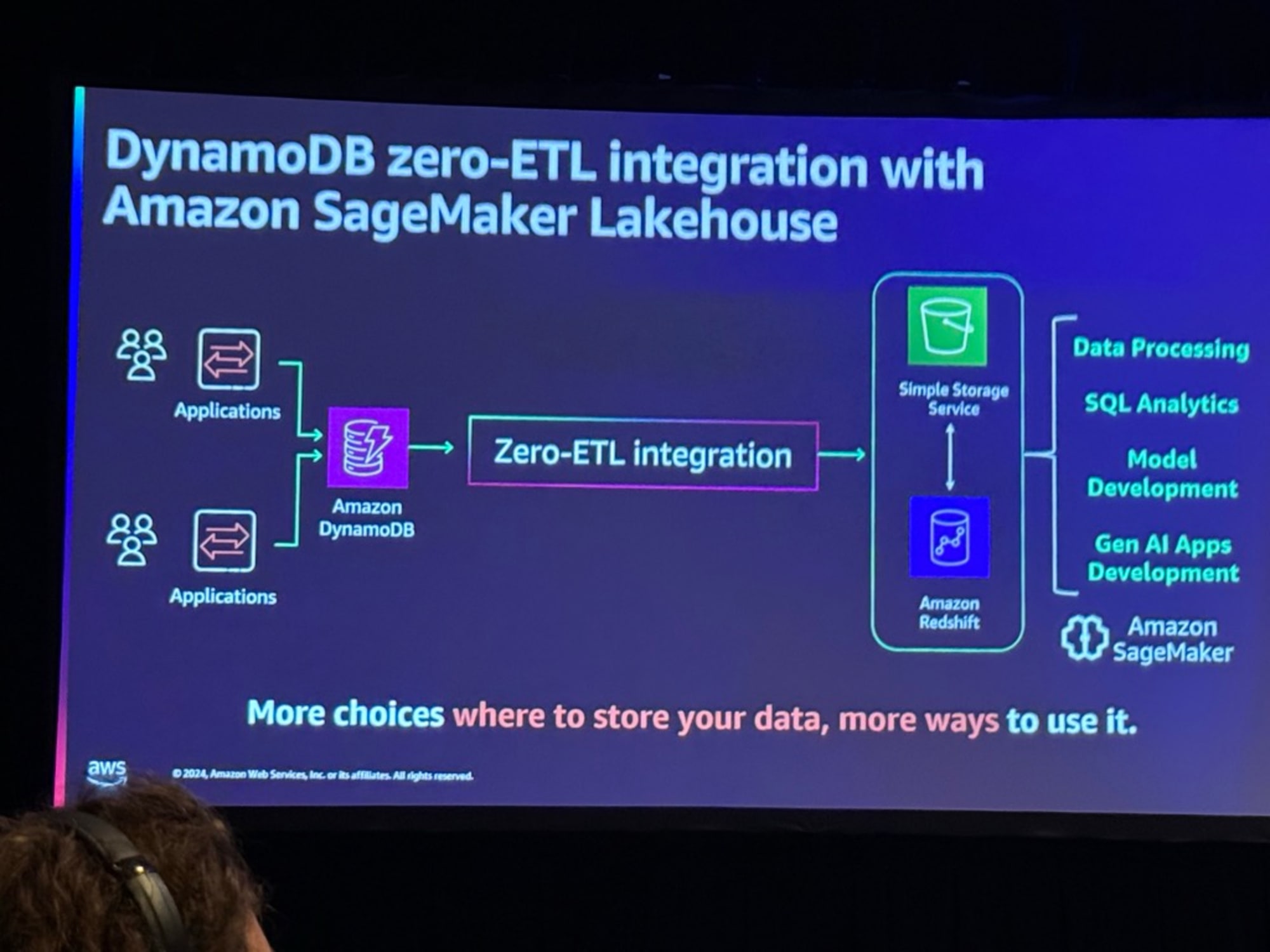
最後にAmazon SageMaker LakehouseとDynamoDBのZero-ETL統合のまとめでした。
- AWSのゼロETLは、複雑なデータパイプラインの管理をAWSがマネージドで自動的に処理する仕組み
- ユーザーはソース、ターゲット、結果のみに集中でき、保守や調整の心配が不要
- DynamoDBからLakehouseへの統合など、データの保存と活用の選択肢が広がり、サーバーレスで従量課金型のため、効率的なデータ管理が実現できる
まとめ
「DAT348 | Deep dive into Amazon DynamoDB zero-ETL integrations」のセッションレポートをお届けしました。
このゼロETL統合の主なメリットとして、俊敏性と効率性の向上、中央集権的なデータガバナンス、運用負担の軽減があり、これによりデータエンジニアの作業を簡素化し、より効率的なデータ管理と分析を可能にすることができるようになります。その結果として、組織はデータをより効果的に活用し、ビジネス価値を迅速に創出することができるようなるのではと思いました。
最後まで読んで頂いてありがとうございました。







